
Disclaimer: Harvey is a legal guidance tool, not a substitute for professional legal advice. The responses it generates are based on the Salvadoran legal framework and jurisprudence available at the time of training and may not reflect subsequent legislative reforms. In cases involving irreversible consequences, deprivation of liberty, loss of parental rights and/or asset forfeiture, always consult a licensed attorney. The model may make errors in areas of high normative ambiguity or where no consolidated jurisprudential criterion exists.
Understanding the problem
The approach to building AI models specialized in law has always been the same: make the model memorize all the laws of the country. And this approach has always been wrong, because the model never learns the reasoning patterns behind the legal framework being applied.
A model that memorizes laws still doesn't know why a judge made a particular decision, which rules were relevant to that specific case, or how to resolve a situation where two laws contradict each other. That's not legal reasoning, that's a glorified search engine.
A better approach is to give the model access to those laws through Tools, and let it decide which laws to look up based on the user's query, training it exclusively on legal reasoning patterns.
Data scarcity
The most important factor for building competent, high-quality AI models is having a good volume of quality data, and in the legal domain that's nearly impossible.
Searching through HuggingFace, the only datasets of judicial resolutions I found were from Brazil and France, and their quality wasn't particularly high. For El Salvador, nothing existed.
Since my goal was for the model to learn legal reasoning patterns, I researched and found the Jurisprudencia website of El Salvador, where I could obtain these reasoning traces.
This government site publishes judicial resolutions (public domain data), and they contain a summary of the case, which laws were applied, why they were applied, and their respective citations. However, this information wasn't structured in a Q&A (Question & Answer) format, which is the format used to train LLMs (Large Language Models).
Dataset creation
To build the dataset, information was extracted directly from the Jurisprudencia website, collecting judicial resolutions and their respective metadata, primarily those published between January 2025 and March 2026.
Here are some charts of the extracted data (6,643 documents):
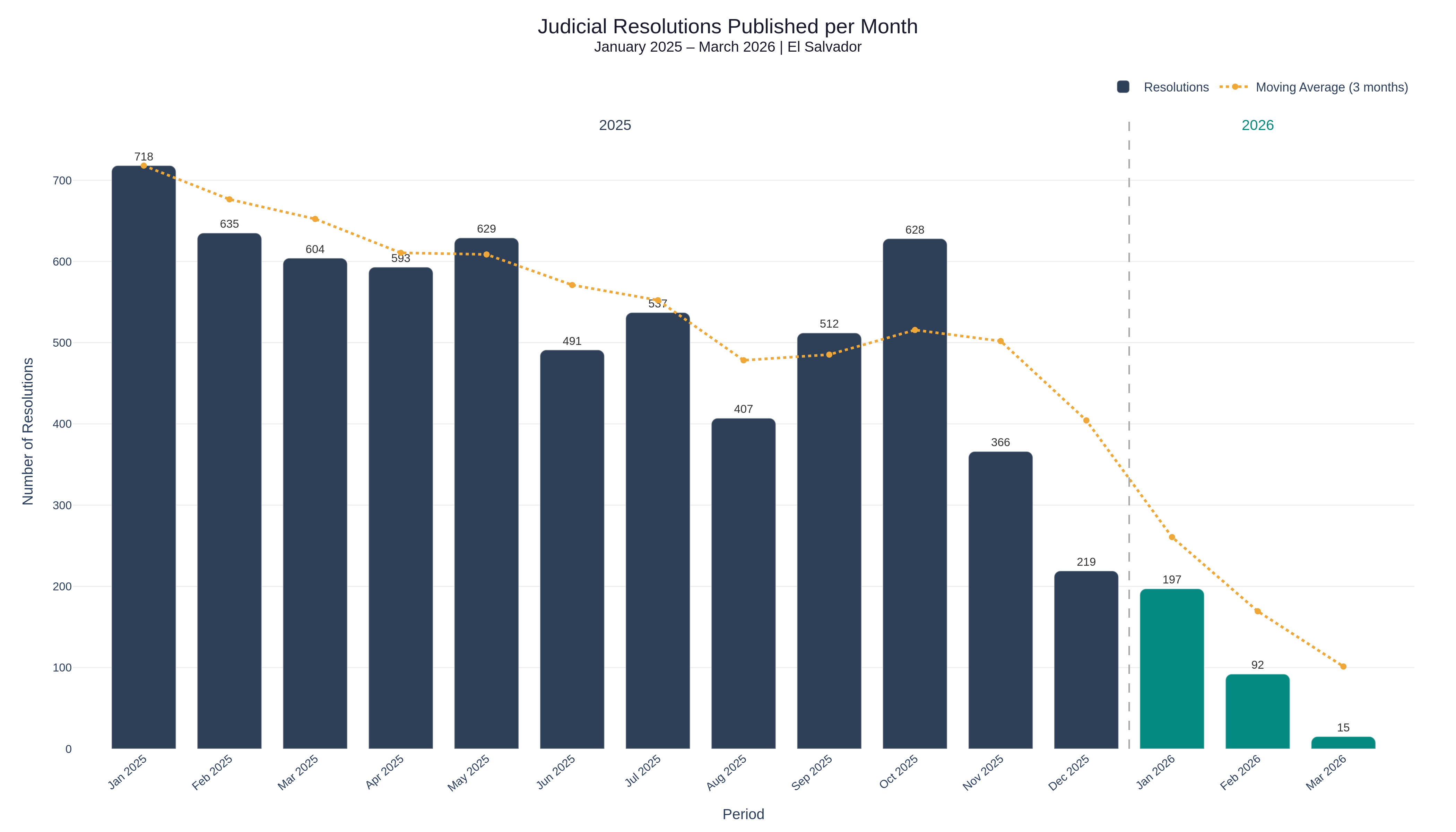
Distribution of Resolutions by Month
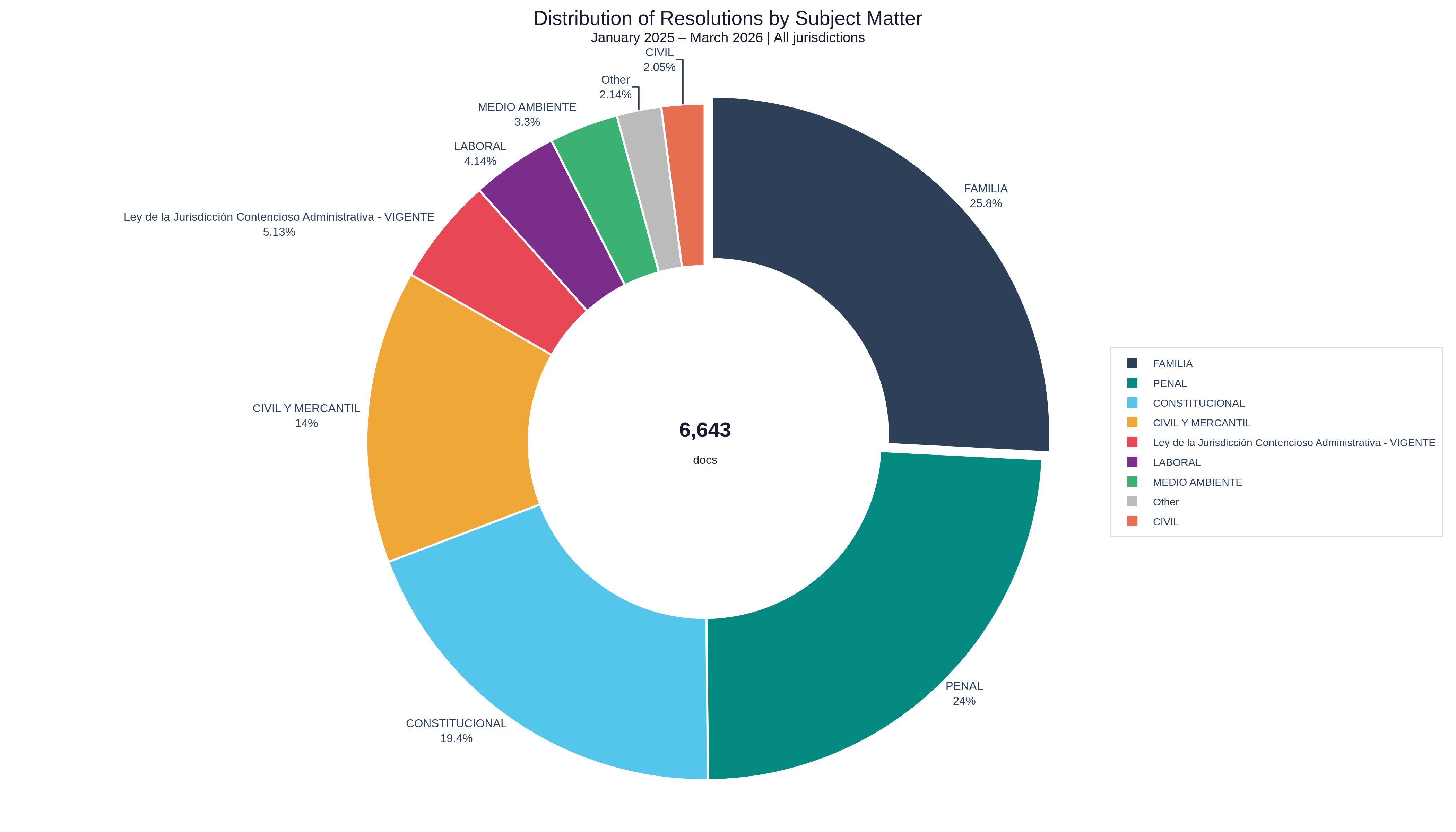
Distribution of Resolutions by Subject Matter
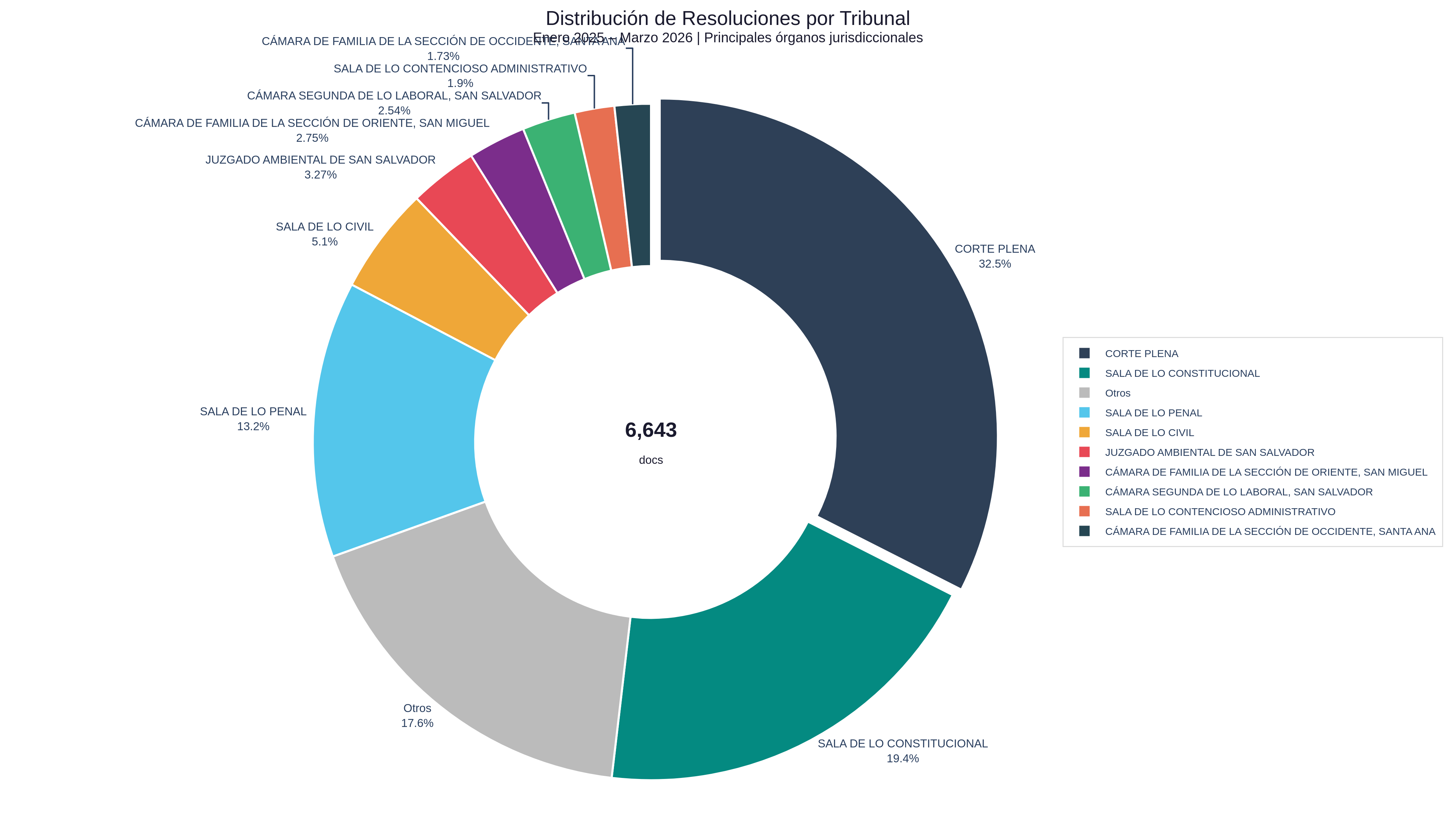
Distribution of Resolutions by Issuing Court
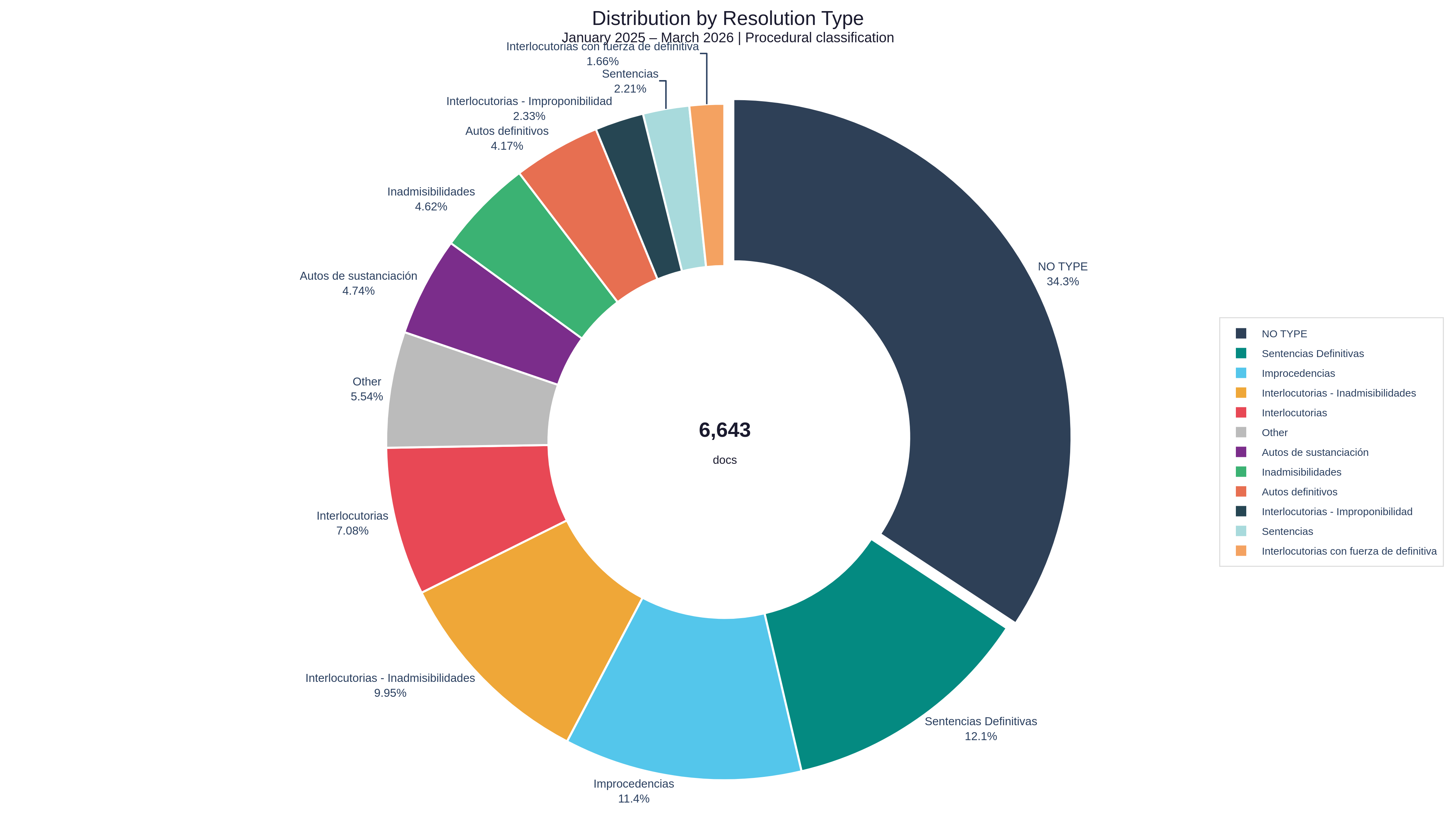
Distribution of Resolutions by Type
Distribution of Resolutions by Year

Now comes the filtering step, selecting documents that contain everything needed for our dataset: the factual background, well-condensed documents that clearly explain the case, the proven facts, the laws applied, etc.
Note: The factual background (cuadro fáctico) is the reconstruction of the facts that the court considers proven and on which the entire legal decision is based.
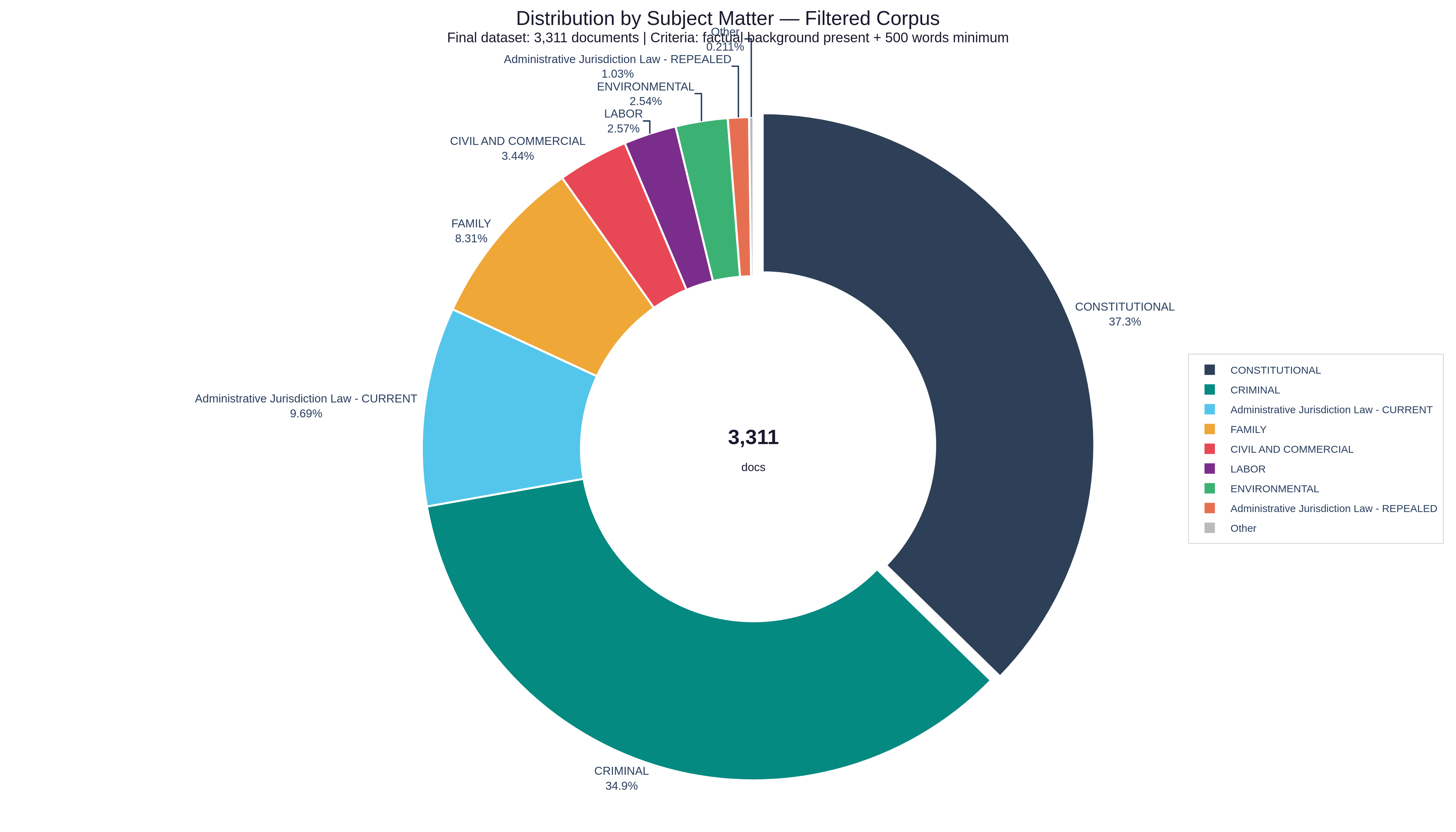
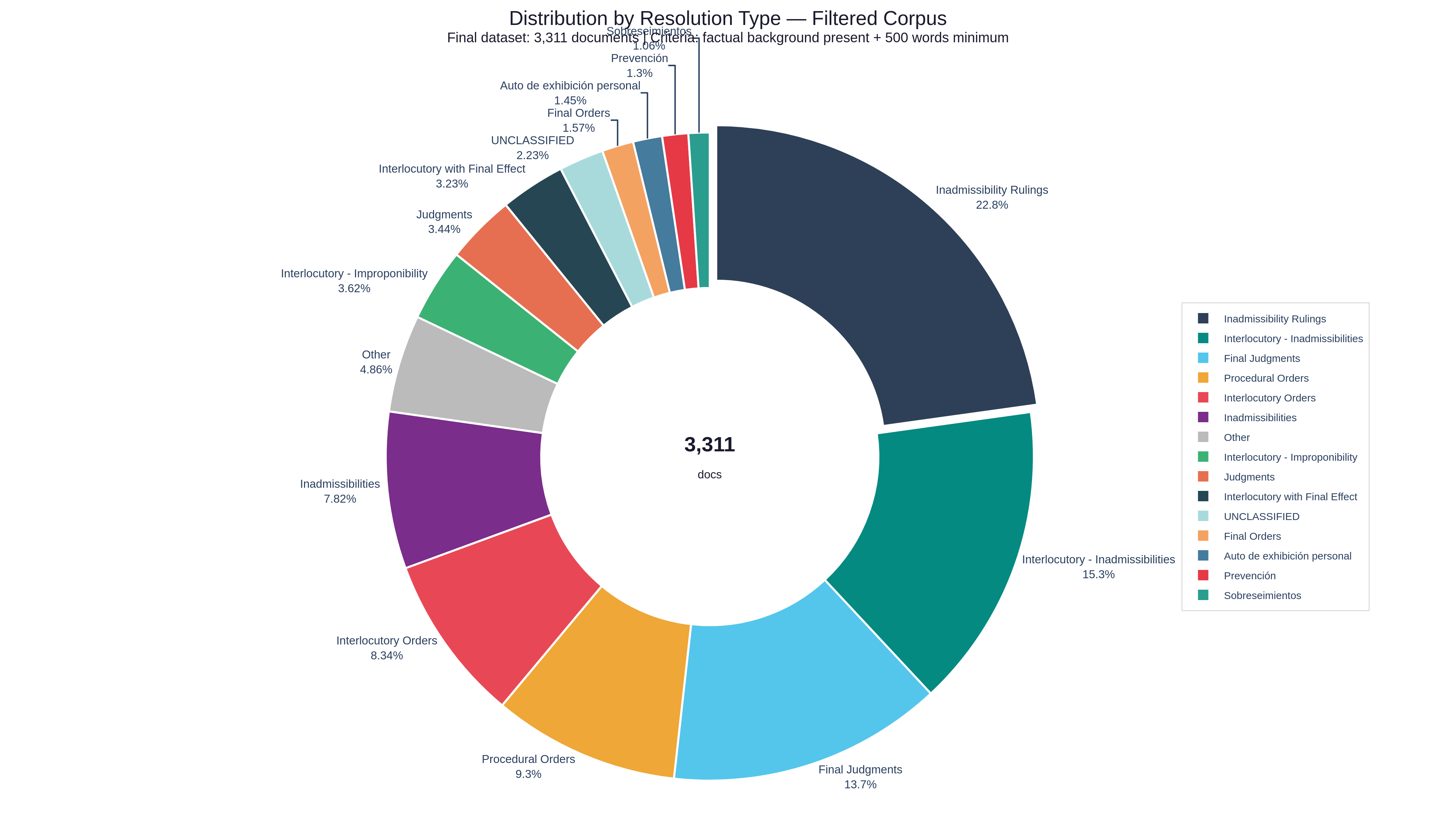
After filtering all documents with the criteria mentioned above, we arrived at the following dataset distributions (3,311 documents):
Distribution of Resolutions by Subject Matter
Distribution of Resolutions by Type
We now have a filtered dataset from which structured legal reasoning can be extracted. However, it still needs to be transformed into the right format for training. To do this, synthetic data will be generated from the obtained corpus using a knowledge distillation approach assisted by a higher-capacity model (teacher). From a reduced subset of highly filtered and verified examples, question-answer pairs are induced that preserve the legal content, incorporating semantic, contextual, and formulation variations, with the goal of improving the student model's generalization.
Synthetic data
For synthetic data generation, the gpt-oss-120b model was chosen as the teacher model, due to its high reasoning capacity and solid performance on complex tasks. This model belongs to OpenAI's latest generation of open-weight models, with approximately 117B total parameters and a Mixture-of-Experts architecture, which allows it to activate only a fraction of its parameters per inference, achieving a balance between capacity and efficiency.
As the student model, huihui-ai/Huihui-Qwen3.5-9B-abliterated was used, selected for its high capability density for its size, showing strong performance on complex reasoning tasks despite its lower parameter count.
Additionally, this model supports modern capabilities like tool calling and multimodal processing (text and images), making it suitable for real-world scenarios where the input isn't purely structured text.
Finally, an abliterated variant was chosen (meaning one with reduced safety restrictions) to avoid refusals on queries related to sensitive topics within the legal domain. This is especially relevant in legal contexts, where it's common to deal with cases involving violence, crimes, or complex situations that might be blocked by models with more restrictive alignment.
Generation system design
The teacher model doesn't just receive the raw text of a resolution and hope for something coherent. That's a very common mistake. Each request to the teacher model is a structured combination of inputs and control parameters that determine exactly what type of question-answer pair should be produced.
The inputs: what information came from each resolution?
For each document in the filtered corpus, the following elements were extracted:
-
Issuing Court: Who resolved the case, which defines the hierarchy and scope of application of the jurisprudential criterion.
-
Subject Matter: The area of law involved (criminal, civil, labor, family, etc.), necessary to contextualize the applicable rules.
-
Resolution Type: Whether it was a final judgment, a dismissal, an appeal resolution, etc. Not all resolutions carry the same legal weight.
-
Factual Background: The reconstruction of the facts that the court considered proven. This field is the most critical: it anchors all reasoning to a concrete situation and prevents the teacher model from fabricating scenarios that don't correspond to the actual case.
In addition to the factual background, the complete resolution document is included, containing the legal analysis, the cited rules, and the final decision. The factual background together with the full document context give the teacher model everything it needs to reason from the facts to the legal conclusion, replicating the logical structure of a judge.
How to generate diversity in the dataset?
A common mistake in synthetic data generation is always producing the same type of example. If all Q&A pairs have the same shape, the student model learns a superficial pattern instead of real reasoning.
To avoid this, each generation introduces 3 independent control variables:
-
User profile: The question must be framed from the perspective of whoever is asking. A citizen asking "can they take my kids away for that?" is not the same as a lawyer asking "what criterion has this court established regarding the weighing of the child's best interest against the parent's right to defense?". The language, level of technicality, and appropriate response are completely different in each case.
-
Complexity level: From questions about a basic concept and a single rule, to analyses where multiple laws are articulated, normative contradictions are identified, and the reasoning explains why alternative interpretations were rejected.
-
Type of reasoning required: Identifying which principle or right was at stake, explaining what criterion the court established, applying that criterion to an analogous case, or resolving a tension between two rules. Each type trains a distinct legal skill.
The combination of these 3 variables across thousands of different resolutions produces a dataset with high contextual, semantic, and resolution variance that gives the student model the patterns it needs to understand what's being asked of it.
Constraints
One of the most notable problems of any AI system, and one that becomes far more dangerous in the legal context, is false certainty: giving a definitive answer when the correct answer is to acknowledge that no definitive answer is possible.
And this is a design and framing problem with these systems. LLMs are trained to always give the user an answer, and they're penalized for "I don't know how to answer that" or "I don't have enough context to resolve your question." So, from the dataset itself, examples were introduced where the correct answer isn't a legal conclusion, but an explanation of why that conclusion isn't possible without more information or professional legal advice.
This provides some level of safeguards when the user's query doesn't contain enough information or when the case is genuinely ambiguous.
Output format
Each generation produced an object with three fields:
{ "question": "...", "reasoning_answer": "...", "final_answer": "..."}-
question: The question in Spanish, framed according to the parameters described above. -
reasoning_answer: The legal reasoning chain in English. Many of these AI models are trained to generate an internal chain of thought in English, and to avoid collapse errors when training the student model, it was decided to maintain this standard. -
final_answer: The response in Spanish, generated from everything above.
Generated examples
Fine-Tuning
Now that we have the dataset generated in the right format, we can proceed with fine-tuning to create Harvey. As mentioned earlier, the huihui-ai/Huihui-Qwen3.5-9B-abliterated model will be used along with our own training framework called Kronos.
The configuration to launch training is as follows:
from kronos.data import Datasetfrom kronos.text import KronosTrainQwen3_5
dataset = Dataset( name="Harvey-Dataset", size="full") trainer = KronosTrainQwen3_5( model_name="huihui-ai/Huihui-Qwen3.5-9B-abliterated", dataset_size="full", dataset=dataset, wandbkey="wandb-key", lora_r=32, lora_alpha=64, lr=1e-4, max_steps=620, batch_size=2, gradient_accumulation_steps=16, eval_steps=100)
trainer.train()Why these parameters?
lora_r=32 and lora_alpha=64 define the capacity of the LoRA adapter. The rank r controls how many trainable parameters are added to the base model. A value of 32 is sufficient for the model to learn complex legal reasoning patterns without requiring the memory that full fine-tuning would demand. lora_alpha is the scaling factor that controls how much weight the adapter updates have over the model's original weights; the convention of using alpha = 2 × r keeps that balance stable during training.
lr=1e-4 is the learning rate, which defines how large the steps are that the optimizer takes when updating weights. With LoRA and instruction datasets, a value of 1e-4 is conservative and stable: high enough to learn in a reasonable number of steps, but low enough not to destroy the general capabilities the base model already has.
batch_size=2 with gradient_accumulation_steps=16 gives an effective batch size of 32. Instead of processing 32 examples simultaneously (which would exceed available memory), the model processes 2 examples at a time for 16 steps, accumulating gradients before making a weight update. The mathematical result is identical to a batch of 32, but with a fraction of the required memory.
Convergence and overfitting
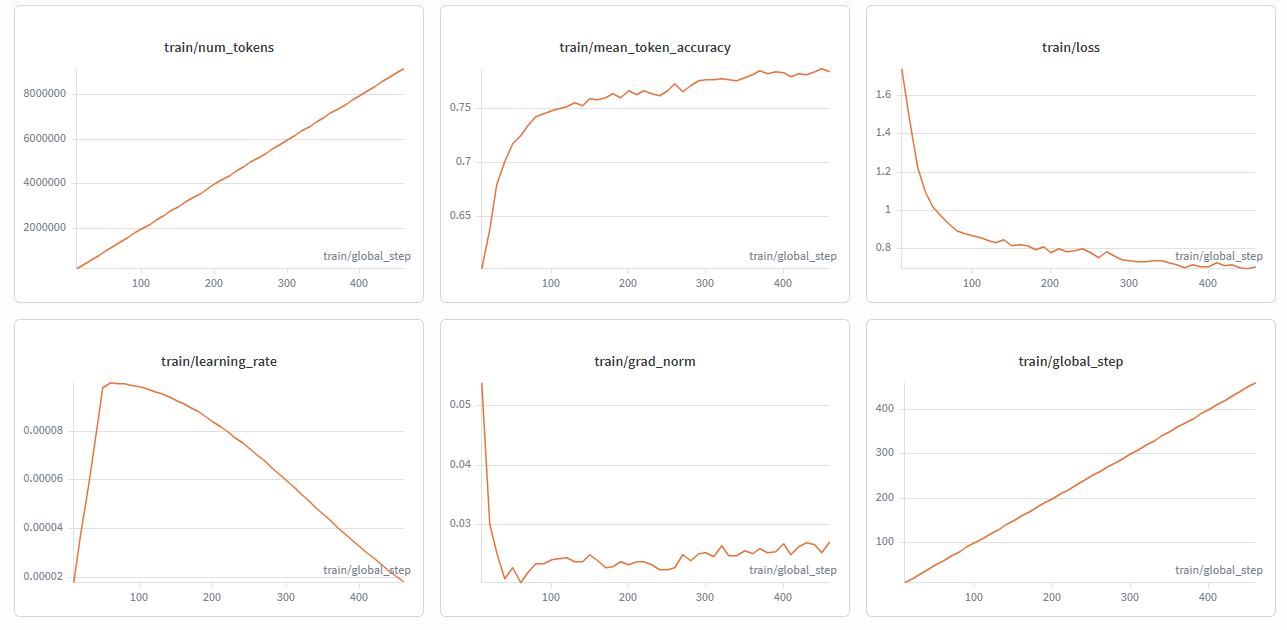
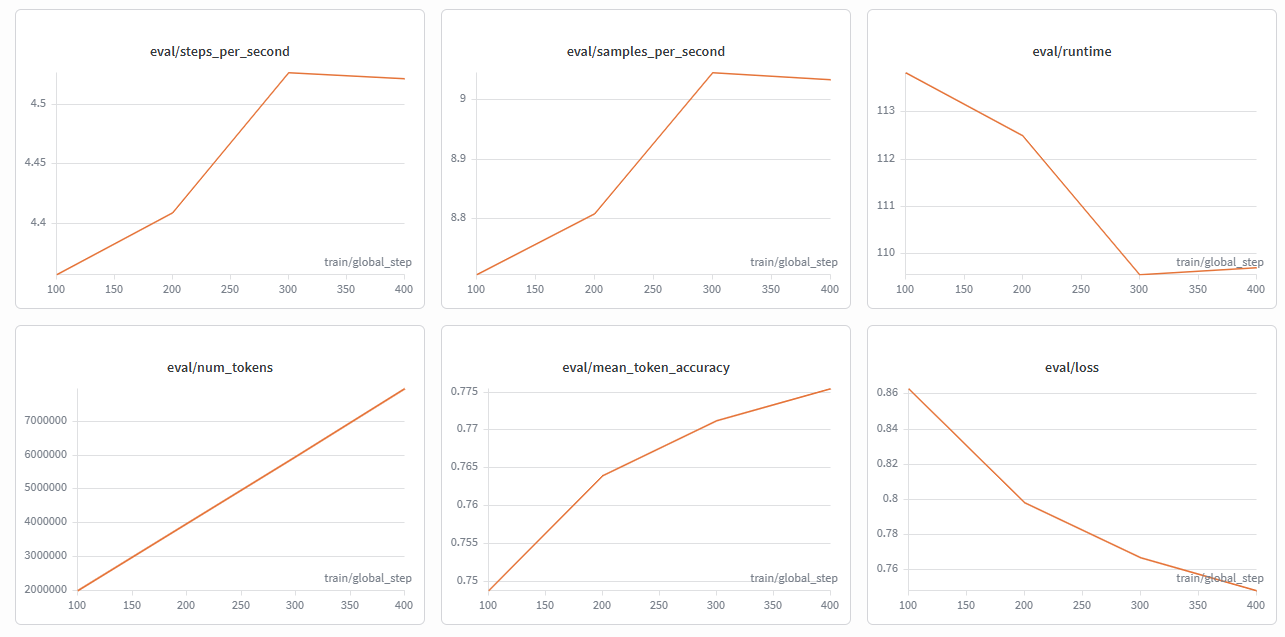
During training, two key metrics are monitored in parallel: train/loss (the error on the training data) and eval/loss (the error on a validation set the model never sees during training).
Convergence happens when both metrics stop dropping significantly: the model has learned the patterns the dataset can teach, and each additional step yields diminishing returns.
Overfitting is the opposite and more dangerous scenario: where train/loss keeps dropping but eval/loss starts rising. This means the model stopped learning generalizable patterns and started memorizing specific training examples. A model that memorizes instead of generalizing performs well on data it has already seen, but fails on real queries that were never part of the dataset.
Initially, the model was going to be trained for 620 steps, equivalent to about 2 full epochs over the Harvey dataset. However, monitoring the curves in W&B, it was observed that around steps 380–400 both train/loss and eval/loss converged around 0.70–0.74, with a gap between them of just 0.038. This is a signal that the model was generalizing correctly without memorizing. Continuing beyond that point would have only increased the risk of overfitting without real improvements in reasoning quality, so training was stopped at 450 steps.
Training Metrics
Evaluation Metrics
Using Harvey
To demonstrate Harvey in action, we deployed the model on Modal (a platform that gives us access to GPUs to run AI models). We're using an Nvidia RTX PRO 6000 and, as the inference engine, vLLM, which lets us serve Harvey with an API compatible with OpenAI SDKs.
This is the code used to deploy Harvey:
import modalimport json
vllm_image = ( modal.Image.from_registry("nvidia/cuda:12.8.0-devel-ubuntu22.04", add_python="3.12") .apt_install("git", "curl", "build-essential",) .entrypoint([]) .run_commands( "python -m pip install --upgrade pip", "python -m pip install --upgrade setuptools wheel" ) .uv_pip_install( "vllm==0.19.0", ).run_commands( "pip install --no-deps transformers==5.5.0 huggingface-hub==1.9.0" ) .env({"HF_XET_HIGH_PERFORMANCE": "1", "VLLM_VIDEO_FETCH_TIMEOUT": "120"}) )
MODEL_NAME = "Aquiles-ai/Harvey-9B"
hf_cache_vol = modal.Volume.from_name("huggingface-cache", create_if_missing=True)vllm_cache_vol = modal.Volume.from_name("vllm-cache", create_if_missing=True)
app = modal.App("vllm-inference")
N_GPU = 1MINUTES = 60VLLM_PORT = 8000
@app.function( image=vllm_image, secrets=[modal.Secret.from_name("huggingface-secret")], gpu=f"RTX-PRO-6000:{N_GPU}", scaledown_window=15 * MINUTES, timeout=30 * MINUTES, volumes={ "/root/.cache/huggingface": hf_cache_vol, "/root/.cache/vllm": vllm_cache_vol, },)@modal.concurrent( max_inputs=100)@modal.web_server(port=VLLM_PORT, startup_timeout=30 * MINUTES)def serve(): import subprocess
cmd = [ "vllm", "serve", MODEL_NAME, "--served-model-name", "Harvey-9B", "--async-scheduling", "--host", "0.0.0.0", "--port", str(VLLM_PORT), "--reasoning-parser", "qwen3", "--enable-auto-tool-choice", "--tool-call-parser", "qwen3_coder", "--api-key", "dummyapikey", "--max-model-len=102400", "--gpu-memory-utilization=0.90", "--trust-remote-code", "--mm-encoder-tp-mode", "data", "--mm-processor-cache-type", "shm", "--media-io-kwargs", json.dumps({"video": {"num_frames": -1}}), ]
print(cmd)
subprocess.Popen(cmd)Note: For more details, you can check the Modal documentation.
To access the model, we'll use our platform Ishikawa, where we'll create a Workstation and upload the Salvadoran Penal Code. Internally, when the file is loaded, the system automatically generates a contextual index. For documents over 120 pages, accessing information this way is much more efficient: if the model can answer the question using just this index, it does so instantly. But if it determines it needs a greater level of detail, it will call a Tool to extract the exact text from the document.
The following images showcase the model's response when presented with a specific case and granted access to this contextual index.
Case: In my proceedings, the prosecution filed an appeal in cassation against the verdict acquitting a defendant of sowing and cultivation. It was argued that the Chamber engaged in a defective assessment of evidence and violated the principle of sufficient reason, pursuant to Art. 478 No. 3 of the CPP. However, the Criminal Chamber upheld the Chamber's criteria, determining that its argumentation was legally and logically valid; conversely, one magistrate issued a dissenting opinion, considering the analysis of the body of evidence to be incomplete. How does this court resolve the tension between the requirement of the principle of sufficient reason and the assessment of evidence in cases of sowing and cultivation?
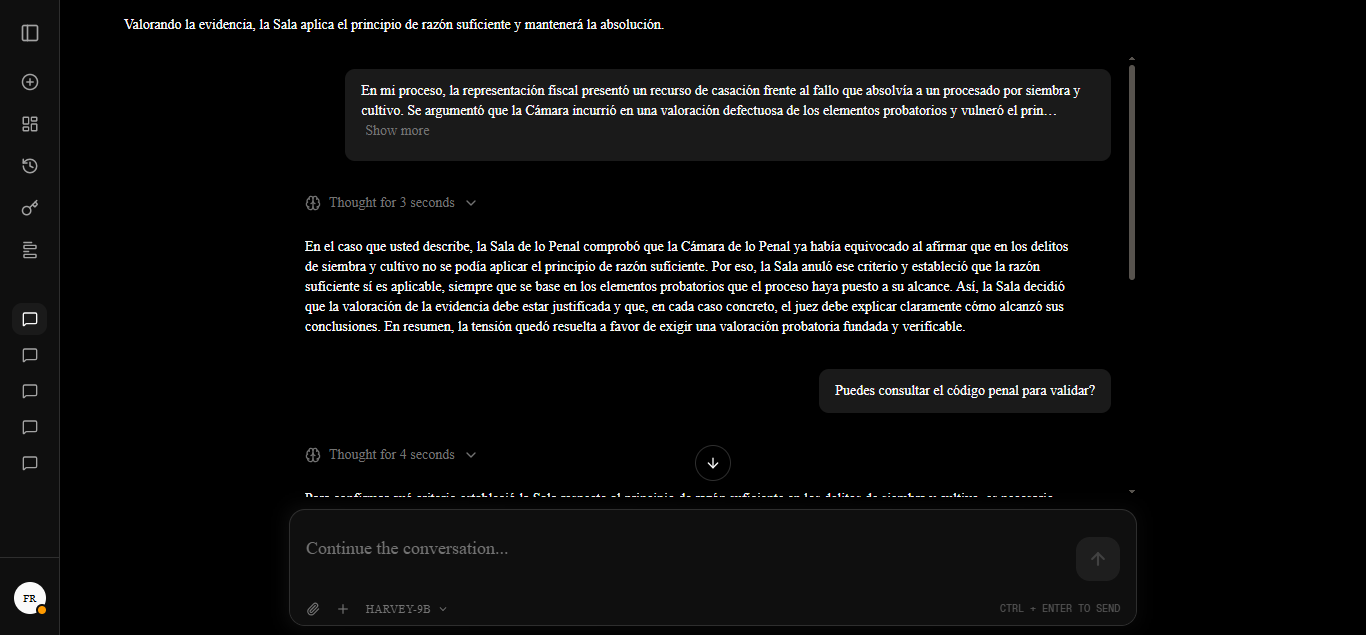
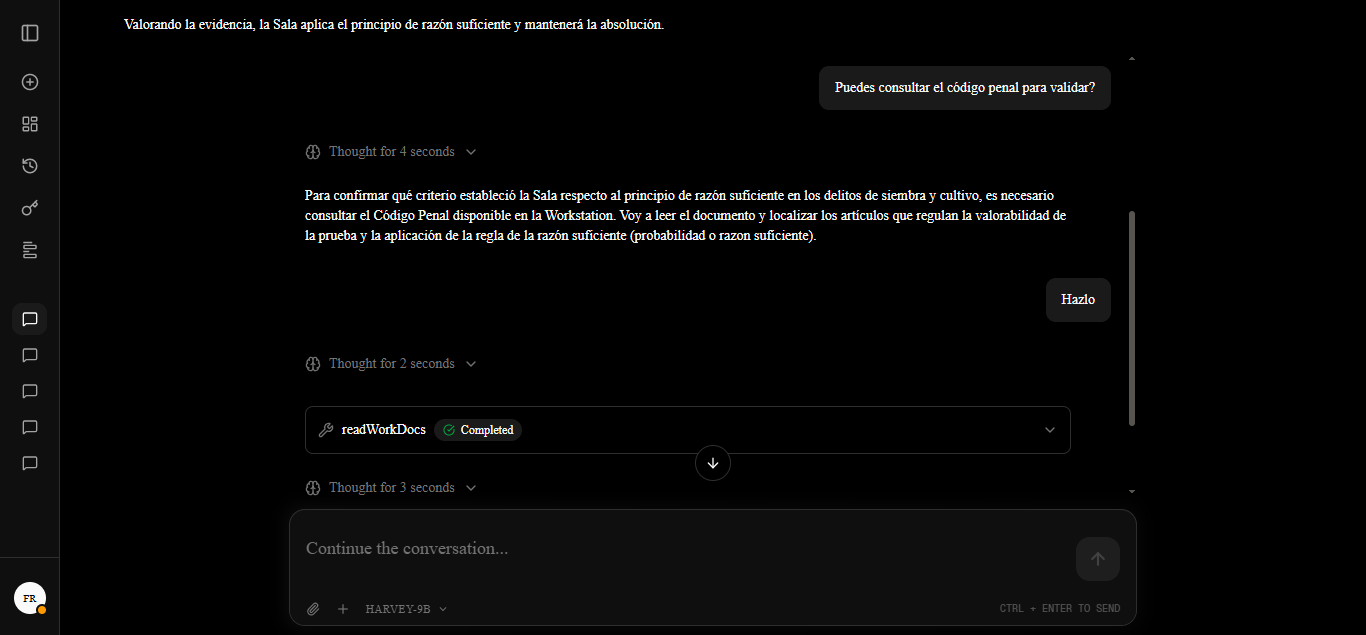
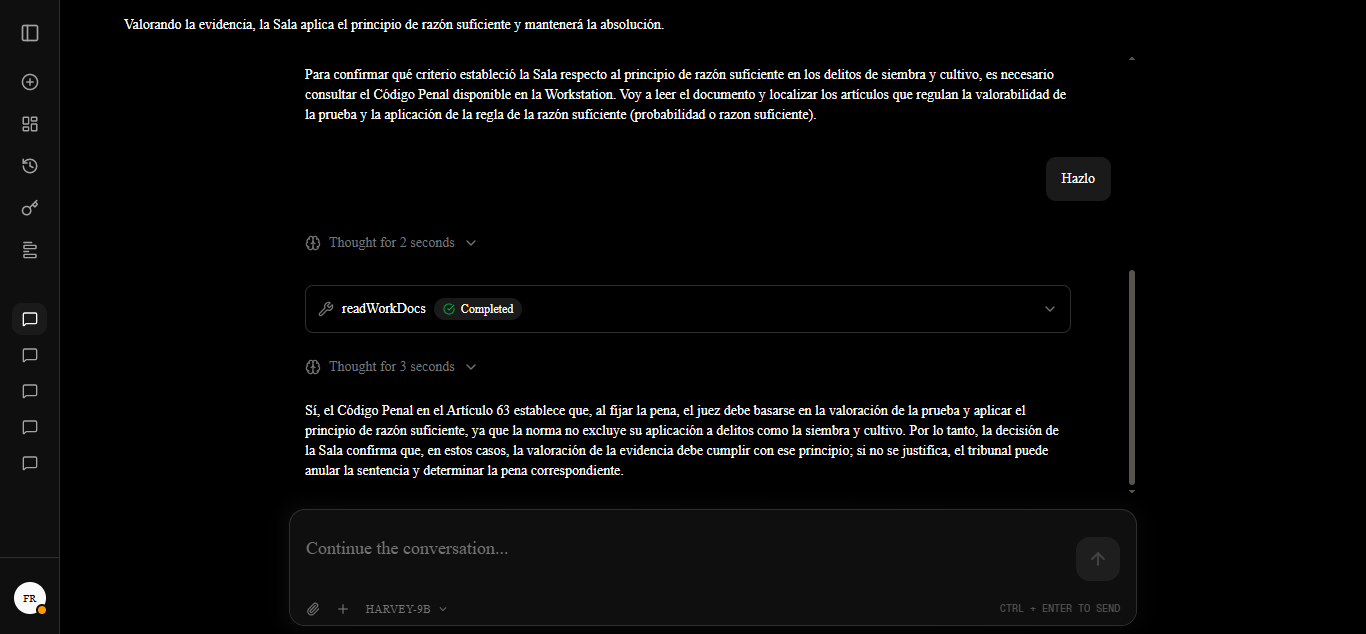
Note: While Harvey successfully integrates legal reasoning patterns and possesses the architecture required for tool invocation, its activation autonomy is currently in a reactive stage. In certain scenarios, the model requires additional reinforcement or a "nudge" within the prompt to trigger autonomous legal queries. Nevertheless, the system meets its core objectives: deep legal reasoning capabilities and the technical ability to ground itself in current regulations via external tools when requested.
Conclusions
Harvey is not a finished product; it's a proof of concept that demonstrates it's possible to build an AI model specialized in legal reasoning for a specific legal system, using public data, open-source tools, and without massive infrastructure.
What exists today that didn't exist before: a structured corpus of Salvadoran judicial resolutions, a legal reasoning dataset in Q&A format with reasoning traces, and a 9B parameter model trained on all of that and publicly available.
The limitations are real. Harvey works well in cases where jurisprudence is clear and consolidated, where the reasoning follows patterns the dataset was able to cover. It fails or becomes imprecise in areas underrepresented in the corpus, in legislative reforms after March 2026, and in cases where the outcome depends on very specific facts that no model can evaluate without more context. That's why the disclaimer at the top isn't decorative.
What comes next is continuing to expand the dataset toward other subject areas and time periods, evaluating the model more rigorously with legal-specific metrics, and exploring whether this approach scales to other Latin American legal systems with similar characteristics.
References and resources
- Model: Aquiles-ai/Harvey-9B on HuggingFace
- Teacher model: openai/gpt-oss-120b
- Base student model: huihui-ai/Huihui-Qwen3.5-9B-abliterated
- Data source: Jurisprudencia de El Salvador
- Training framework: Kronos
- Inference platform: Modal
- Inference engine: vLLM
- Usage platform: Ishikawa
- Knowledge Distillation: Arxiv 2402.13116
- LoRA: Arxiv 2106.09685
- Brazil legal datasets: HuggingFace
- France legal dataset: HuggingFace